| 赤池情報量規準 AIC (Akaike Information Criterion) |
赤池弘次博士が考案。当てはまりのよさを追求するあまり、複雑なモデルを多用するのではなく、ケチの原理から、より簡易なモデルを利用するために採用される、当てはまりの良さを示す指標の1つ。AICが最小となるモデルが最適。 |
| 一対比較法(いっついひかくほう) Method of Paired Comparison |
| 2者のうち、どちらが良いか1つを選ぶ比較的簡単な設問でアンケートなどに多用されている。 Excel回帰分析でもデータ解析が可能である。 [AHP法、Excel用アドインプログラム「一対比較法プログラム」] |
| 移動平均 |
時系列データなどで、増減の激しいデータでも、移動平均を求め、それをグラフに表すことによって、データは平均化され、傾向をつかむことが容易になる。
|
| L4直交表 | ||||||||||||||||||||||||||||||||||||||||||||
| 以下のような表をL4直交表と呼ぶ。 実験計画法なら、要因が3つ、実験回数が4回のデータをこれに当てはめることができる。 L4のLは「ラテン方格(Latin Square)の略。4は、行数を表している。 ちなみに、このL4直交表は、上表の「2」を-1に置き換えて考えることで、直交表の成り立ち(割付の要領)が理解できる。
|
| L8直交表 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
以下のような表をL8直交表と呼ぶ。
実験計画法(要因計画法)で、要因(因子)と水準を割り付けるのに用いられる。 多元配置実験計画法に比べて、実験回数は少ない。 2水準の要因が7つある7元配置実験計画法の場合の実験回数は、27=128回となる。 ちなみに、このL8直交表は、上表の「2」を-1に置き換えて考えることで、直交表の成り立ち(割付の要領)が理解できる。
直交表は、実験計画法(要因計画法)で用いられる、できるだけ少ないデータ(実験回数)から、より多くの情報を得るのに役立つ。 [実験計画法、要因計画法、直交表、計画行列、タグチメソッド、Excel用アドインプログラム「直交表作成プログラム」、Excel用アドインプログラム「超らく解析プログラム」、Excel用アドインプログラム「影響度分析プログラム」] |
| Excelのグラフ機能 |
| Excelの5大機能の1つ。 用途に応じてどのグラフを使い分けるかを考えるのが重要。 常に基データ(グラフ作成用データ)とグラフは連動しており、描画されたグラフ(棒グラフならその長さ)を変更すると、基データもその変化に応じて数値が変更される。 [円グラフ、折れ線グラフ、3-D(スリーディー)縦棒グラフ] |
| (データマイニングにおける)Excelの5大機能 |
| データマイニングの一貫した作業がExcel上でできることから、次のように定義する。 ・グラフ機能 ・ピボットテーブル機能 ・分析ツール ・統計関数 ・ソルバー 特に分析ツールやソルバーは、ぜひ活用したい機能である。 なお、一般にExcelの4大機能または5大機能のようにして挙げられる事柄としては、表計算機能・グラフ機能・集計機能・分析機能・文書作成機能などがある。これらの機能は、データ周りの一連の作業がExcelで可能になることを示している。 もっとも、統計解析の分野では専用ソフト(SPSSやS-PLUS等)に、文書作成ならばワープロソフト(Wordや一太郎等)にはかなわない。 [Excelのグラフ機能、分析ツール、ソルバー] |
| 円グラフ |
| 円グラフは、比率(全体を100%とし何%あったか)を把握するのにすぐれたグラフ。 データ要素が少ないときには特に有効。また、データ要素が多い場合でも、データ数値の差が大きい時には有効だが、そうでない場合にはグラフ化しても差が分かりづらく、視覚化の効果が得られない場合がある。 |
| 折れ線グラフ |
| 時系列データの変化を見るときにより有効なグラフ。 Excelのグラフ・ウィザードで簡単に折れ線グラフが描ける。 |
| 回帰係数 |
回帰式の中で、 |
| カイ自乗検定における自由度 | ||||||||||||||||||||
一般に、m行×l列の
それぞれの合計値を基に、5と8の数字さえわかってしまえば、その他の12、10、20、18は無くても求めることができる、つまり合計値を基に、最低限必要なのは5と8(もちろん8と12や10と20でも良い)の2個だけで充分、すなわち、自由度=2というようになる。 |
| 間隔尺度 |
数字の中で、日付・時刻(時間ではない)や気温、がこれにあたる。 |
| 記述統計学 |
データを要約して、そのデータの特徴を記述する統計(学)のこと。 |
| 基本統計量 |
データを要約するときに使用する種々の統計量。平均値(単純平均、幾何平均、調和平均)中央値(メディアン)、最頻値(モード)、標準偏差などがある。Excelでは分析ツールの基本統計量を選択すると、一度に求めることができる。 |
| 近似曲線 |
| 折れ線グラフや散布図に追加する線。追加することで、データの増減の傾向を見ることができる。 Excelのグラフ機能でサポートしている曲線(直線)には、線形近似、対数近似、多項式近似、べき乗近似、指数近似、移動平均がある。 これらの遣い分け方は、データの傾向により使い分ける必要がある。 また、闇雲に当てはめればよいというものでもない。 |
| クラスター分析 |
多変量解析手法の1つ。 |
| クロス表 |
| 分割表ともいう。属性の数により2重クロス表、3重クロス表、…がある。Excelでは、クロス表を求める場合、ピボット・テーブルを使う。クロス表のより高度な分析には、カイ自乗検定や双対尺度法などが有効である。 |
| 計画行列 | |||||||||||||||||||||
実験の計画をあらわした表のこと。次のような表のことを「計画行列」と呼ぶ。 このようなデータから、要因(この場合は「温度」と「触媒」)の違いにより生成量を求めるモデルをExcelで簡単に求めることができる。 |
| 工程能力指数 |
工程能力指数(CP)は、特に工業の品質管理でしばしば使用され、皇帝の維持管理改善に用いられている。 |
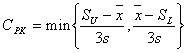
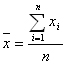
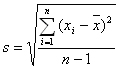
| 最小自乗法 |
| 散布図の各マーカーから直線まで縦軸と平行に線を引く。この線分(誤差・残差)を自乗すると正方形の面積になる。正方形の面積の和が最小になるように、回帰式のaとbを決定する方法。 線分の長さを最小にするよりも数学的に扱いやすいため、この方法が採られている。(平均すると0に近くなり、自乗することで全ての差が正の値になる) 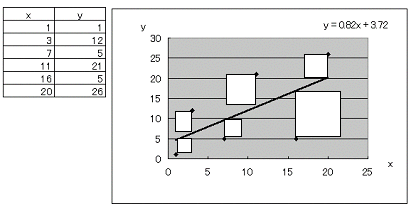 |
| 最適な回帰モデル |
説明変数の中で、本当にyに対して効いているもので、過不足なく回帰モデルを構成することがポイントである。ケチの原理といって、出来るだけ少ない説明変数で回帰モデルを作るべきである。 |
| 最適な回帰モデル作成法 |
| EXCELの回帰分析ツールを用いて、説明変数減少法により、最適な回帰モデルを求める。 まず、すべてのアイテムを用いて回帰分析を実行し、P-値(危険率)が最大な説明変数を減らして、再度、回帰分析を実行する。アイテムが一つになるまで繰り返す。モデルの候補の中で、説明変数選択規準 が最大のものを最適なモデルとする。 上田の規準: R: 重相関係数 [Excelアドインツール 50B 「最適な回帰モデル」、重相関係数] |
| 最頻値(モード) |
| 最頻値とはファッションモードのモードと同じように、最も多い数字のこと。4,6,8,8,8,9,9,10,11,13の最頻値は8。 Excelでは、MODE関数で簡単に求められる。しかしこのMODE関数では、最頻値が2つ以上存在していても、1つしか表示されないので注意が必要。 |
| 3元配置実験計画 |
|
実験計画法の1種で、要因(因子)が3つの場合の時を指す。 |
| 散布図 |
対になったデータを横軸、縦軸で平面上にプロットしたグラフで、データの様子を捉えるには極めて有効である。対になったデータを解析するには、まず、散布図を描くとよい。外れ値などを見つけることができる。 |
| シグマ Sigma (Σ、σ) |
| ギリシャ文字で18番目の文字。 大文字は「Σ」 小文字は「σ」 大文字のΣは、データの総和(すべて足し算する)を表す。 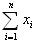 ちなみに、このような記号を専門書で見かけるが、これは、1番目のデータxの値から1つずつ順番に最後のデータxまでの値をすべて足し算する、という意味。つまりデータの合計値(ExcelではSUM関数)を意味する。 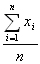 ちなみにこれは、上記の合計値をデータ数で割り算したもの。平均値(相加平均、ExcelではAVERAGE関数)を表す。 小文字のσは、標準偏差(Standard Deviation)を表す記号として、よく使用されている。 [総和(合計)、標準偏差、偏差、自由度] |
| 実験計画法 |
| 「要因計画法」とも呼ぶ。注目するデータ(生成量・不良率など)の増減に影響を及ぼすと考えられる要因(「因子」とも呼ぶ)と水準(それぞれの要因の条件を指す)を採り上げ、水準をいろいろ変化させ実験を実施する。 得られたデータ(特性値)に要因がどのように効いているかを調べ、また要因ごとの水準がどのような組み合わせの時に特性値が最大(または最小)となるかを調べる。 解析には分散分析法が一般に使用されるが、回帰分析でも解析可能であることが重要なポイントである。Excelでも充分解析できる。 [要因計画法、特性値、要因、因子、水準、分散分析、回帰分析、Excelアドインツール 50A 「超らく解析プログラム」、Excelアドインツール 510 「影響度分析プログラム」] |
| 重回帰式 |
| y=a+b1x1+b2x2+b3x3…bkxkの式のこと。aをy切片、b を回帰係数という。最小自乗法を用いて を求める。 xを説明変数、yを被説明変数という。複数の説明変数でyを表わす式である。回帰式、回帰モデルとも呼ぶ。 xが1つのときが単回帰式である。回帰モデルは予測と要因分析に用いる。 |
| 重相関係数 |
重回帰式の良さを示す指標で、0と1の間の値をとる。一般には1に近いほど良い回帰式である。 [最適な回帰モデル] |
| 順序尺度 |
| 成績などの順位や、アンケートなどでよく見かける、次のような数字が順序尺度にあたる。 ● 当店をご利用になった感想をお聞かせ下さい。 Q1: 従業員の接客態度 = 5.大変満足 4.満足 3.普通 2.やや不満 1.大変不満 [名義尺度、間隔尺度、比例尺度] |
| 推測統計学 |
| 標本(サンプル)データから、母集団の統計量(平均値、標準偏差など)を推測する統計学。 これに対して、「記述統計学」がある。 [標本(サンプル)、母集団、記述統計学] |
| ステレオグラム |
| Excelでは、グラフウィザードの「3-D(スリーディー)縦棒グラフ」のこと。2つの属性の項目に関連があるか、あるいは違いがあるかを視覚的につかむのに適している。 クロス表をグラフ化するにはこのステレオグラムがよい。 次のようなタイプ別良品・不良品のデータをステレオグラムで作成すると、以下のようになる。  |
| 数量化理論Ⅰ類 |
| 林知己夫博士が提案した統計手法。ダミー変数を用いた回帰分析モデルであることがわかっている。Y(回帰モデルの被説明変数のこと)を外的基準という。外的基準をアイテム・カテゴリデータ(ダミー変数のこと)で表現し、回帰係数に相当するカテゴリ・スコアを求める。カテゴリ・スコアは定性的な情報を数量化したものである。 [ダミー変数、Excelアドインツール 50A 「超らく解析プログラム」、Excelアドインツール 510 「影響度分析プログラム」] |
| 数量化理論II類 |
林知己夫博士が提案した統計手法。外的基準が定性的で2グループのときはダミー変数を用いた回帰分析モデルであることがわかっている。y(回帰モデルの被説明変数のこと)を外的基準という。外的基準をアイテム・カテゴリデータ(ダミー変数のこと)で表現し、回帰係数に相当するカテゴリ・スコアを求める。カテゴリ・スコアは定性的な情報を数量化したものである。 [ダミー変数、Excelアドインツール 50A 「超らく解析プログラム」、Excelアドインツール 510 「影響度分析プログラム」] |
| 説明変数選択規準 |
重回帰分析において、最適な回帰モデルを求めるための説明変数選択規準として、以下のようなものがある。 |
| 相関の有無のt検定 (無相関の検定) |
|
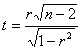 は自由度
は自由度| 相関の有無を判定する簡便法 |
| 次の式が成り立つと相関があると判定する。 この式でrは相関係数のこと。 相関係数が0.73でデータ数が15個の場合、式に当てはめると、0.73の二乗が0.53で、4/17の0.24より大きいので、統計的に相関があると判定する。 [相関、相関の有無のt検定] |
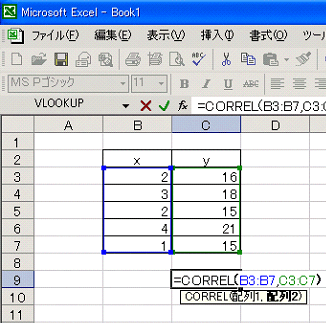
| 相関係数 | |||
| ある量とある量との線形な関係度を表わす指標で-1と1の間の値をとる。1に近いときは強い相関があるといい、-1に近いときは負の強い相関があるという。単回帰式の良さの指標でもある。 xが増えるとyも増えていくというような関係を正の相関関係があるといい、xが増えるとyが減っていくような関係は負の相関関係、どちらの傾向もみられないような場合は、無相関という。 相関係数rは次の式で求める。
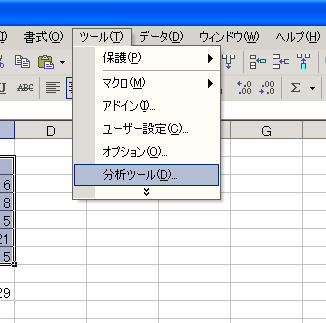
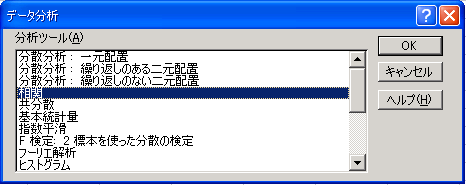
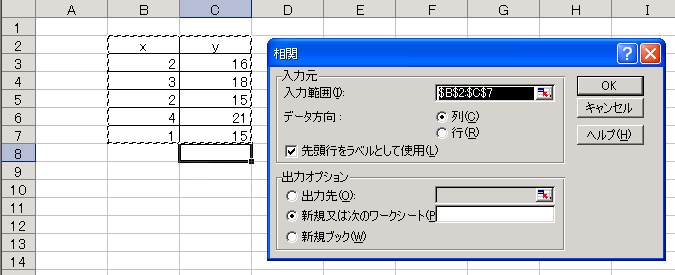
Excelでは統計関数CORRELを使うか、Excelのアドイン「分析ツール」の中の「相関」機能で簡単に求めることができる。 [相関の有無を判定する簡便法、相関の有無のt検定、相関係数、自由度、t分布] ● CORREL関数で求める場合: ●分析ツールで求める場合: |
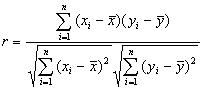
| ソルバー |
ソルバーとは、解決するツール。問題を解く(Solve)ツールという意味。 |
| 代表値 |
| 集められたデータはいくつかの数値に要約することができ、この要約に用いられるものが基本統計量と呼ばれる。 分布全体を1つの数値で示すために考えられた統計量のことを、代表値と呼ぶ。 代表値には、次のような種類がある。 ・平均値 = 単純(相加)平均、幾何(相乗)平均、調和平均 ・中央値(中関数、中位数、メディアン) ・最頻値 など。 [単純平均、幾何平均、調和平均、中央値、最頻値] |
| タグチメソッド Taguchi Method |
品質工学とも呼ぶ。田口玄一博士が半世紀かけて開発した画期的な工学手法。 |
| 多元配置実験計画(たげんはいちじっけんけいかく) |
| 実験計画法(「要因計画法」とも呼ぶ)の中で、要因(因子)が2個の時を、2元配置実験計画、3個の時を、3弦配置実験計画と呼ぶ。■要因の時は「■元配置実験計画」となり、これらを一般的に「多元配置実験計画」と呼ぶ。 [実験計画法、要因計画法、2元配置実験計画、3弦配置実験計画、要因、因子、計画行列] |
| ダミー変数 |
| {好き、嫌い}、{男、女}など定性的な情報を0,1データであらわして、回帰式を求めることができる。この0,1データのことをダミー変数という。数量化理論1類はダミー変数を用いた回帰モデルである。 |
| 単回帰式 |
| y=a+bxの式のこと。aをy切片、bを傾きあるいは回帰係数といい、xでyを表わす一次式である。xを説明変数、yを被説明変数という。最小自乗法を用いてa,bを求める。 単とは説明する変数xが1個であるからである。(複数個のときは重回帰式という。) ちなみに、y切片とは、xが0の時のyの値を表す。(「定数項」とも呼ぶ) |
| 縦棒グラフ |
| データを比較するのに最適なグラフ。 Excelでは、一般に表の左または上から、順番に棒グラフで表されるので、表データとグラフとで表示順序を変えたい場合は、表データとは別に、グラフ作成用の表を作ることがお勧めである。 |
| 中央値(メディアン) |
| データを小さい順にならべたとき、ちょうど真ん中(中央)にある値のこと。データが偶数個のときは、中央の2つの平均値が中央値である。 平均は極端に小さい値や極端に大きな値が変化すると影響されるが、中央値は影響されないのが特徴。データが正規分布の場合は、平均値=中央値になる。 Excelでは統計関数MEDIANで求めることができる。 なお、平均値だけではなく、中央値や最頻値も求めるべきということもあるが、やはり分布や層別の傾向の違いを探る・比較することにはかなわない。 [代表値] |
| 直交表 |
| 要因(因子)と水準を効率よく割り付けられるように作られた表のこと。 2水準系(各要因につき水準が2つずつある): L4、L8、L16、L32、L64 3水準系(各要因につき水準が3つずつある): L9、L27、L81 タグチメソッド系: L12、L18、L36 などがある。 列同士が直交しているところに特徴がある。計画行列そのものである。 [実験計画法、計画行列、タグチメソッド、直交表作成プログラム、ダミー変数、Excelアドインツール 50A 「超らく解析プログラム」、Excelアドインツール 510 「影響度分析プログラム」]] |
| データウェアハウス |
| データの倉庫のこと。通常は膨大な(ギガバイト、テラバイト級)データを入れる。データマイニングとデータウェアハウスはペアで使われる。著名な商品にEss Base、Red Brick、DIAPRISMなどがある。 |
| データ工学 |
統計学、データマイニング、タグチメソッド、人間工学、感性工学など周辺関連手法・工学を駆使してデータ解析し、有効な知見や知識などを求める工学手法のこと。 |
| データマイニング |
| データマイニングとは通常膨大なデータをマイニング(採掘)して宝物(情報・知見・知識・課題・仮説など)を見つける手法・プロセスのこと。代表的な手法には統計、ニューラルネット、パターン認識などがある。データマイニングツールのことをシフトウェアと呼んでいる。 |
| 尖度(せんど、とがりど) |
尖度はデータの分布を描いたときどのくらい尖っているのかを示す統計量のこと。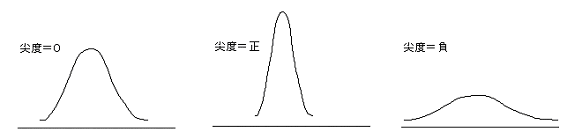 上述の式は定義式で、Excelの場合の計算式は次のようになる。 Excelでは、KURT関数で求められる。 |
| ノン・パラメトリックな検定 |
|
例えば、t検定は、母集団が正規分布に従うことがわかっている時に使うことができるが、その反対に母集団の分布に制限無く使うことができる検定を、ノン・パラメトリックな検定と呼ぶ。 |
| 2元配置実験計画 |
|
実験計画法の1種で、要因(因子)が2つの場合の時を指す。 [3元配置実験、計画行列] |
| 外れ値 |
| 数値データのなかで、極端に大きな、あるいは小さな値をとるデータのこと。異常値、例外値、特異点ともいう。シフトウェアを用いて外れ値をみつけ、原因を追求することで知見が得られることがある。データマイニングらしい手法の1つ。 また、3σで求めることもできる。 [データマイン君] |
| ばらつき |
| データのちらばり具合をばらつきという。ばらつきを表わす統計量には、標準偏差、レンジ(範囲)がある。 [基本統計量] |
| パラメトリックな検定 |
| 母集団の分布が正規分布などに従うものとしてその分布のパラメータ(平均値、標準誤差)の知識を使う検定のこと。 [母集団、正規分布、平均値、標準誤差] |
| パレート図 |
| 縦棒グラフと折れ線グラフを組み合わせた複合グラフのこと。 重要な項目は何かを見極めるのに適している。複数の項目の中から影響度の高いものをみつけることができるため、その対策をとっていくことができる。 また、影響度の高い項目が、全体の何割を占めているかということが視覚的に分かるのがパレート図の特徴。 不良データをパレート図にすると、以下のようになる。パレート図作成には、降順(大きい順)で並べ替えた個数データと、その個数の累積比率が必要。 販売管理ソフトや会計ソフトなど、基幹業務系ソフトでは、ABC分析ができる機能を有しているものもある。 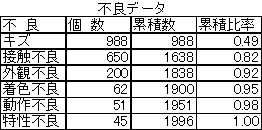 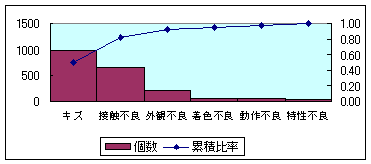 |
| ヒストグラム |
ある数値からある数値までの間にデータがいくつあるのかを表わす棒グラフ。データの分布の形を見るのに適している。また、データ全体の特徴をとらえるのに使用する。 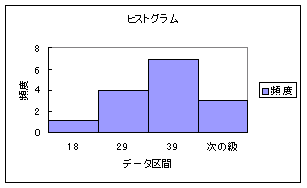 |
| ピボットテーブル(Excel) | ||||||||||||||||
| Excelで表データから、2重クロス表や3重クロス表を自在に作成できる機能などがある。 行列を自由に入れ替えることができるので、さまざまな角度からの分析ができる。 1) 表データを用意する 2) ピボットテーブル(メニューバー「データ」→「ピボットテーブルとピボットグラフ レポート(P)」を選択) 3) 画面表示・該当する範囲指定等を行う 4) 作成したいクロス表の形になるよう、項目を選択する 5) 完成例: → example_031.xls (約25KB)
また、出力されたピボットテーブルの、例えば21のセルをダブルクリックすると、女性でauを所有する21人の詳細データが別シートに表示される。 ここで作成された「クロス表」は、ほかに「分割表」とも呼ぶ。 [クロス表(分割表)、ダブルクリック、カイ自乗検定] |
| 標準化 (基準化) |
| (データの)基準化とも呼ばれる。 データの標準化の方法の1つとして、次のような方法がある。 複数のデータ(データ行数が2以上のことではない)について、比較・検討しやすいように、尺度を変換する方法のこと。 平均(単純平均)は必ず0、標準偏差は必ず1となるようにするのが、標準化である。 標準化の方法は次の通りである。 1)No.1~No.10までの10個のデータがある。 この10個のデータの平均値(Excelでは、AVERAGE関数)を求める。 2)10個のデータの標準偏差を求める。(Excelでは、STDEV関数) 3)まずNo.1のデータについて、次の計算をして、標準化させた値を求める。 ([No.1の値]-[10個の平均])÷[10個の標準偏差] 4) 3)の計算をNo.2からNo.10についても行う。 5)全ての標準化させた値の平均値は0になり、どの項目においても、同じ |
| 標本 |
| 東京都に住む20代女性の、携帯電話所有率を調べる場合、20代女性の全員のことを母集団と呼ぶ。 現実的には、20代女性全員を調査して所有率を求めるのは不可能である。そこで、ランダムに500人を抽出した場合、この500人が標本(サンプル)数となる。 500人の回答結果から、母集団の所有率を求めることを推定と呼ぶ。このような統計学のことを、推測統計学と呼ぶ。 「母集団」も参照のこと。 [アンケート調査、サンプルサイズ、母集団、標本数、推測統計学] |
| 標本サイズの決定法 |
| アンケートの調査などで、標本サイズ(サンプルサイズ)をいくつにすれば良いかが問題になる。 標本サイズを決定する簡便法として、次のような式で求められる。 eは誤差(%)である。 eを5%とすると、 eを1%だとすると、この要領で計算して、データ数は最低10000あれば良いことがわかる。 [アンケート調査、サンプルサイズ、母集団、標本数] |
| 標準偏差 (Standard Deviation) |
標準偏差はばらつきを表わす統計量である。 |
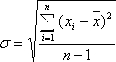
| 比例尺度 |
| 一般に、数量データ、量的データと呼ばれる。 数の大小にも意味があり、比(当月の月商300万円は前月比の2倍)や、差(前年と比べて年商が2000万円多い)を求めることにも意味を持ち、0は、その数が無いことを示す。(売上が無かった、時間の0はその時間が無かったことを示し、気温の0度などとは意味が異なる) [間隔尺度、名義尺度、順序尺度] |
| 品質工学 |
| 「タグチメソッド」を参照のこと |
| 分析ツール(Excel)、データ分析ツール |
| Excelでサポートされている統計分析機能。 基本統計量・ヒストグラム・相関係数行列・分散共分散行列・回帰分析など、19種類サポートしている。(Microsoft Windows版Excel XPの場合) なお、Excel97は、メニューバーの「ツール」メニューを展開することで、「分析ツール」メニューが表示されるが、それ以降のバージョンの場合で、メニューが表示されない場合は、次のような方法で、分析ツールを使えるようにアドインを追加する必要がある。(CD-ROMに標準収録) →→ 「分析ツールを使えるようにする」 (bun_tool.pdf 約56KB PDF形式) [ヒストグラム、回帰分析] |
| 平均値 Mean, Average |
| 平均には通常私たちが使っている相加平均(単純平均)と相乗平均(幾何平均)、調和平均がある。 |
| 偏差値 Deviation Score |
| 常に、平均点を50、標準偏差を10となるように、正規分布の形になるようにしたもの。 |
| 母集団 |
| 東京都に住む20代女性の、携帯電話所有率を調べる場合、20代女性の全員のことを母集団と呼ぶ。 |
| 母数と統計量 |
|
「母数」のことをパラメータ(Parameter)とも呼ぶ。母集団分布の様子を表す数値のこと。 |
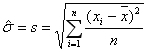
| マルチコ/多重共線性 (Multi-collinearity) |
重回帰分析のデータで、説明変数同士に極端に強い相関がある(見せ掛けの相関、擬似相関など)などの場合に起こり、予測や要因分析の判断を誤る恐れがある。 参考: 関連書籍・共著書など「データマイニングの極Excelで学ぶデータマイニング入門(オーム社)意(共立出版)」、「Excelで学ぶ回帰分析入門」(オーム社)」、「実践ワークショップ Excel徹底活用多変量解析(秀和システム)」、「」など |
| 名義尺度 |
Q:あなたの血液型は? |
| 歪度(わいど、ゆがみど) |
| 歪度とはデータの分布を描いたとき、左右対称からみてどのくらい歪んでいるかを示す統計量のこと。 正規分布 ピークが左 ピークが右 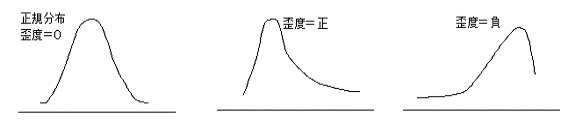
n: データ数 |
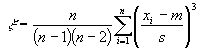
| 要因計画法 |
| 「実験計画法」を参照のこと |
| レンジ(範囲) |
| ばらつきを表わす統計量で、最大値-最小値のこと。 Excelでは統計関数MAX(最大値を求める)と統計関数MIN(最小値を求める)の差からレンジを求めることができる。 [基本統計量] |
| ロジット変換 |
| 次のような変換をすることを、ロジット変換と呼ぶ。 ●式1の これを「ロジット変換の逆変換」と呼ぶ。 |
| y切片(せっぺん) |
回帰式の中で、 |